Initial comparison of Garmin 60CSX and Magellan Explorist 600 reception
Part of the Robert Lipe tech articles, robertlipe at usa dot net
- 2006-02-02 Clarify that more sats can be a better position fix. (Thanx, Fizzymagic!)
- 2006-02-02 Point out that Magellan's positioning average is a mixed bag. (Thanx, Peter!)
- 2006-02-04 Add section on cumulative distance travelled.
- 2006-02-09 Misc formatting fixes.
Background
There has been a lot of anticipation and speculation about the new Garmin "X series", with the most attention given to the new SirfStar III receiver. Though I intend to write up a full comparison between the 60CSX and the Explorist 600, here are the initial results of some studies I was doing while working on GPSBabel for the X series. This page will be updated or replaced as it evolves.
This was originally posted on the Middle TN Geocacher's Club forum but I moved it to my collection of articles. It was originally a series of forum threads which is why it has kind of a wandering, evolving, conversational feel.
I've had two complaints with Garmin's handhelds to date.The absence of removable memory isn't the problem these days as it was in '01 when units with 8MB of map memory roamed the earth. For most people, a routable basemap and 56MB is "enough". (If you're a frequent traveller or go on short notice, it's not.) Still, maps don't get smaller over time. City Select 6 took more space in your GPS than CS5 did. So the effective size of your map memory goes down over time if you want current maps. So it would be nice to be able to throw more memory in a couple of years down the road as a way to extend the useful life of your purchase.
The second was the dealbreaker for me. The reception has been, uuuuh, not great. Since the #1 purpose of a GPS is to tell you where you are, the unit failing to do that when there happens to be a tree visible on the horizon is just bad. It's a pretty well known trait among geocachers.
Garmin addressed both of these problems in their extreme makeover announcement this month. There are some minor tweaks (powers from USB, lower case letters in waypoint names, etc.) but those are the two biggies. There's confusion in the groundspeak forums crediting them with being more accurate, owing to their use of the award-winning Sirf receiver circuitry. That's true mostly as an effect. If you have a fix on the same number of satellites in the same geometry, the accuracy should be the same. Having better reception means having more satellites to choose from. That can lead to better geometry which can lead to better accuracy. Modern receivers will do a simultaneous solution from all the visible satellites, not just from the four with the "best" geometry. The overdetermined solution tends to help ameliorate systematic errors (especially multipath) and gives a slightly better expected error in the position fix.Of course, when you have a poor lock (and the C series will let you wander around for many minutes before divulging that they've lost lock) your accuracy will be poor. But if they both have a lock, they'll both take you to the same place.
As a tangible example, I have a 60CS and a 60CSX side by side at my desk. The X (like the Explorist that's also next to it) has a lock on 9 satellites. The 60CS has a red box saying "Lost satellite reception" and no fix at all. If I take them both near a window, they'll both report coords that are about the same.
Number of Satellites Received
Here's a fun little program and test fixture I put together. I hooked three GPSes (a Magellan Explorist 600, a Garmin 60CS, and a Garmin 60CSX) up at my desk and used a modified GPSBabel to gobble the output of all three at the same time. You can argue that testing GPSes at a desk inside a brick house is contrived and not very useful, but this seems totally consistent with my caching experience with the two units I've had in the woods, but I never had the idea to quantify it this way before.This is a scatter plot showing the number of satellites each one picked up graphed over about three hours.
As you can see, the red line (the 60CS) is pretty sad. Most of the time, it didn't have a lock at all.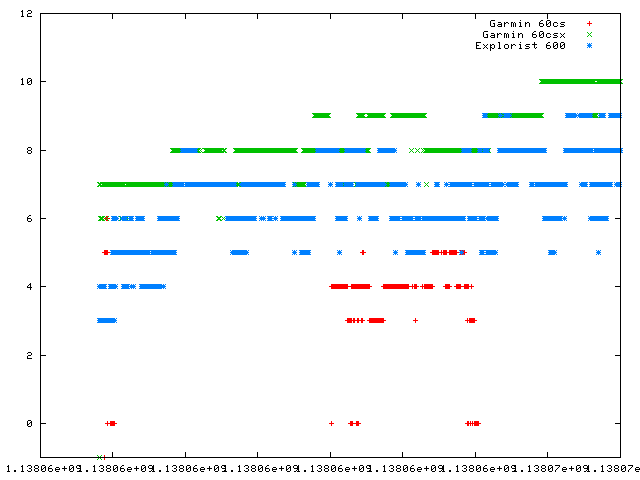
The blue line (the explorist) held a lock 100% of the time with 3-9 sats in view.
The green line (the 60CSX) consistently held a fix on more satellites than the Magellan.
As soon as I figure out how to take a USB hub, a bazillion cables, a bucket full of GPSes, and a laptop 'deep in da woods' without giving myself a hernia or getting mugged, that would be an interesting experiment...
My Ghost Likes To Travel
I may be onto something here. Even if not, I'm having fun making pretty pictures and convincing myself that my observations over the years have been exactly right.If I take the coords that have piled up in the last 6 hours or so and plot them on top of each other, we see the two units that actually have a reliable lock tightly clustering. We see the 60CS wandering around very badly.
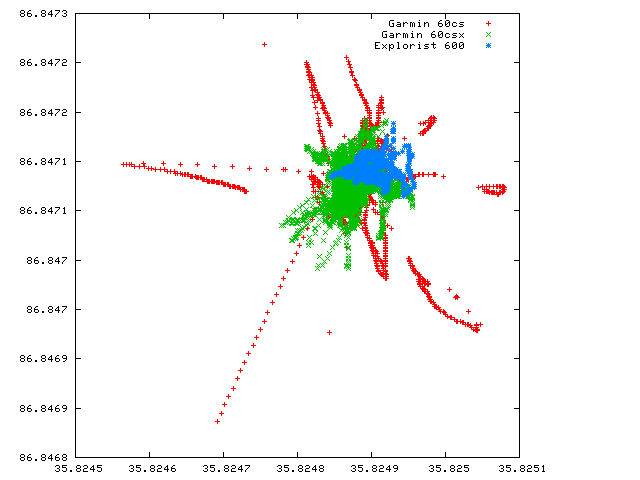
This seems to confirm what I already thought I knew. The 60CS is more likely to let you wander around even when it thinks it has a lock.
So let's take the 60CS out of the graph and keep just the others.
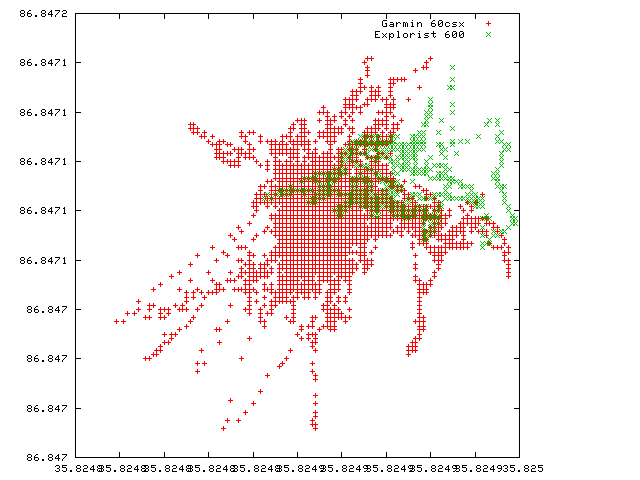
Here it looks like the 60CSX is wandering around but notice that our scale now went beyond the resolution of the key. (Yeah, I should figure out how to change that...)
The most interesting thing is that if we do a straight average of all the data from each receiver, we do get exactly the same coords...
If we look at just the 60CSX and the Explorist, and the number of times that each reported that position, we see something else interesting:
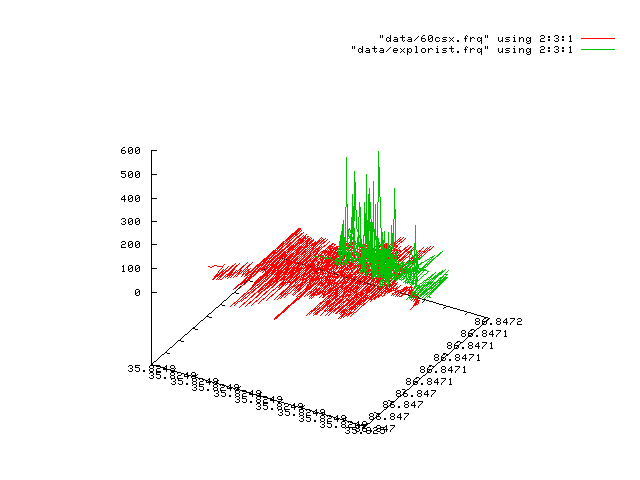
The 60CSX continues to roam within that very small circle; we never get more than 62 identical position reports from any one pair of coords. The Explorist is very confident of its position; returning a smaller "clump" but returning them hundreds of times - as many as 530 for one pair.
It's worth mentioning that the Explorist behaviour may seem 'clearly better', but it's misleading for certain tasks. It seems pretty clear that it's performing an averaging over time. For display on-screen of your position, that's fine. But it's misleading in the NMEA datastream to report "This is your position at time T" when the reality is that it's your positioned over the recent time period T1 through T2. That makes the raw data less useful for further data analysis since it's already been processed to an unknown and variable degree. So if you were in the business of using the NMEA datastream for hyper-accurate positioning, the Magellan's behaviour is probably not what you want. If you were actually moving, or just using this to drive a moving map program, this distinction wouldn't matter.
When in Roam
I was recently asked if the motion observed in the section above tended to come early in the measurements or if the units settled down. To determine that, I modified the GPSBabel style sheet to include the track distance component. Since I then had an output that included timestamps and total distance travel, that was pretty easy to graph: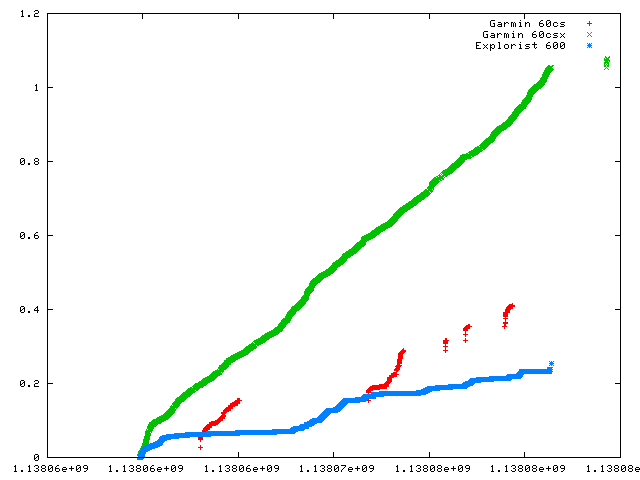
We can see the 60CSX is very steadily drifting around. It travelled over a mile while at my desk. If I view the map screen on the unit and am sufficiently zoomed in, it's pretty black.
The 60CS, since it had no lock, tended to rack up distance quickly in the bursts when it did have a lock as it didn't have opportunity to average for very long and had a poor fix when it had anything at all.
The Explorist readings quickly stablized and levelled off as the positional averaging in that unit kicked in.
Interestingly, there was a period slightly before halfway down the sample period where both units started to collect distances more rapidly. Perhaps the sat geometry at that time was less favorable and both units reacted similarly.
What does it all mean? Which will earn the Grumpy Visioneer's seal of approval? Stay tuned!